Seafile文件系统的设计是模仿Git的。要看懂本篇博客,你至少需要掌握Git的基本操作。如果没有使用过Git,最好还是先学习一下,磨刀不误砍柴工。
最好还能知道一些Git的内部原理,网上有一本开源的图书可以参考:https://git-scm.com/book/en/v2。当然不是要掌握全部Git的内部原理,但至少要知道repository、branch、commit等概念。
概述
Seafile用repo来组织文件的。Repo通常也会被称作library(官方称为资料库)。一个资料库包含brach、commit、fs、block这几个结构,其关系如下:
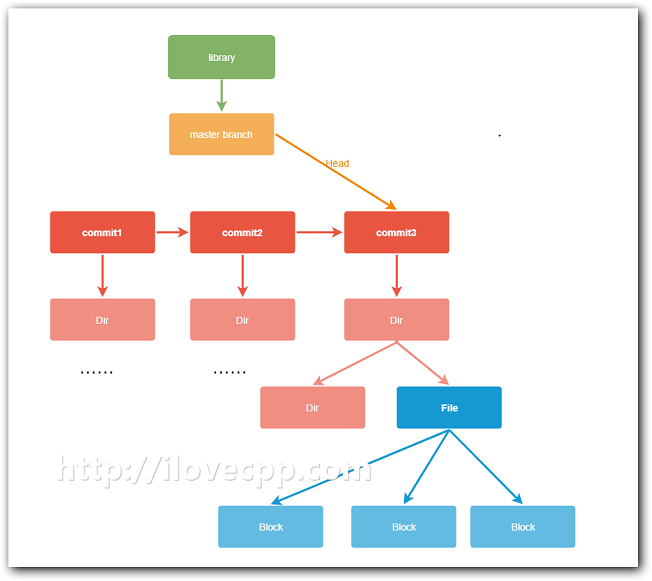
repo
首先是repo,和Git里的repository(仓库)的概念基本是一致的。登录后的Web界面,列出了你所管理所有资料库,这个界面会和Github很相似。
在Seafile内部用一个SeafRepo的结构体表示资料库。
1 | struct _SeafRepo { |
id段是一个36位的UUID,保证了每个资料库都拥有独一无二的ID。name是资料库名,然后就是head,它是一个SeafBrach结构,表示资料库的分支。
branch
分支的概念和Git一样,每个repo都会有分支:
- 在客户端,seafile有且仅有两个分支
local和master,当本地文件时变化时会将修改作用到local分支,然后从服务器下载master分支,最终其合并到local分支。之后在将合并后的分支上传至服务器,服务端将master分支更新至最新的提交。 - 服务端通常只有一个master分支。
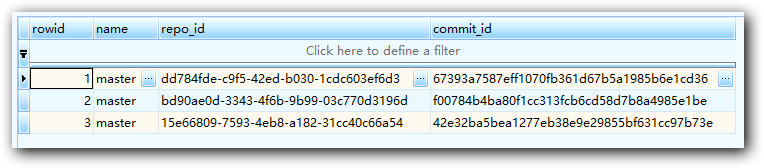
这是用可视化工具查询到的服务端Branch里所有repo的Brach。服务端每个repo只有一个master分支,每一个分支指向了一个commit。
commit
commit的概念和git中基本是一样的,即一次提交。资料库的每次修改都对应了一个commit,因而commit可以看做是目录的一个快照(snapshot),例如现在我又往资料库的根目录下添加了一个文件,此时该资料库的结构就会变成:
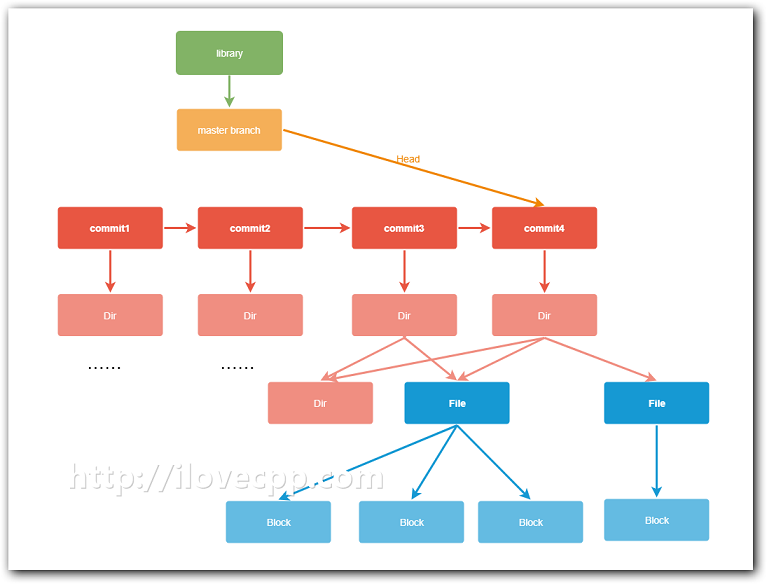
资料库修改后,产生了新的commit:commit4,此时branch的HEAD就指向了最新的commit4。到这里,文件目录结构就会变成:
1 | Library |
git可以通过”git reset –hard commit_id”的方式将当前的的repo回退/前进到仓库的某一个版本。同样这里如果要想把当前的Repo恢复到之前的某一个版本,只需要修改commit,轻松实现文件系统的回退/快进。
如果此时将HEAD重新指向commit3的话,那么资料库就会恢复到之前的状态,刚才添加的File就不见了。正是基于这样的设计,用户可以放心的操作资料库,无论怎么操作,文件都能够轻松的还原到任何的一次快照。
比如说前面Branch里id为”15e66809-7593-4eb8-a182-31cc40c66a54”的资料库当前的commit是”42e32ba5bea1277eb38e9e29855bf631cc97b73e”。commit里的信息是以json存储在硬盘上的文件,找到这个文件并打开:
1 | { |
里边记录整个当前commit的详细信息,其中parent_id指向的是上一个commit,同样打开这个commit可以看到:
1 | { |
这样一层一层追溯下去就能看到,当前Repo的每一次修改记录,通过切换Branch的head可以轻松将资料库回退/前进到任何一个快照。
FS
每一个commit里边有一个root_id,它是资料库的根目录。这也是一个json结构,相当于Linux上的一个inode节点,里边记录了当前目录里边的文件结构。和commit不同这个结构用zlib压缩过,解压后才能看到明文,拿当前的commit举例,它的”root_id”是”9643c57118b2c4c8070fdf32ff7a5693a538defa”:
1 | { |
这个信息表示当前的根目录里边有一个文件,名叫”PIC”,mode字段和Linux上的文件mode位一致,” ‘mode’: 16384, “ 表示这个文件是一个目录,id为”f0857fb999fb00d7ac4b0f42ea04433890c812ab”,按同样的步骤找打这个文件:
1 | { |
说明PIC里边只有一个文件,”‘mode’:33188”表示这是一个普通文件,另外还包含了修改事件等文件属性。根据id”bc61aa586059f275b7398a207a5483868c745ddd”就能找到event.png的具体块信息。到了文件这一级后,并没有包含一个具体的文件路径,而是同样指向了一个id,将这个id打开:
1 | { |
block_ids是一个数组,将这个数组中的每一个块合并起来,就是”event.png”的全部内容。
Blcok
由于Seafile的文件是分块默认的存放路径是:seafile-data/storage/blocks/repoid/blockid,于是这样我们就能定位到event.png的具体内容。
我写了一篇博客专门介绍了seafile文件分块的算法:一种基于内容可变长度文件分块算法的实现。
去重存储
基于这样的设计,同一个文件只需要保存一份。然后将元数据里边的文件id指向同一个就OK了,现在我们在刚才的资料库的根目录新建一个”PIC2”的目录,定位到PIC2的FS元数据后,将其解析:
1 | { |
和上面的PIC目录里的event.png指向了同一个元数据。同时文件属性也能得到正确的表示。仅仅添加了一个占用空间很少的元数据信息。就省掉了一个存储整个文件的消耗!如果把这个png文件换成一个MP4格式的电影,一下就给硬盘减少了上G规模的存储。太酷了!
总结
正是这种基于Git的设计,赋予了Seafile创建文件系统快照的能力,数据的可靠性猜得到了极大的保障。每个资料库的数据存储互相隔离,即使一个资料库损坏也干扰不到其他资料库里的数据。
用元数据记录目录结构,只需要用几十个字节,就能将相同的一个文件,只存储一次,多个地方显示。有了一种基于内容可变长度文件分块算法的实现这样的分块算法后,两个很相似的大文件,也只需要多保存一份差异的数据块。