作为一个支持增量传输、去重存储的同步盘,实现一个高效率的文件分块算法是重中之重。本篇博客在研究了seafile的分块算法之后,将其中的分块算法实现抽取了出来,并详细描述了它基于可变长度分块(Content Defined Chunking)算法的实现。项目托管在Github上:FileCDC。
编译后,直接将文件名作为参数,即可分块:

同时也很方便集成到其他的项目里,调用cdc_work(const char* filename)会将file分块。
基本原理
该实现依赖于Rabin Footprint,俗称Rabin指纹。本文不会(当然也是没能力)深入分析Rabin指纹的数学原理,就像你使用MD5时,无需关心MD5是如何计算的。Rabin算法能够根据前一个数据块的指纹快速得滑动窗口后下一个数据块的指纹:
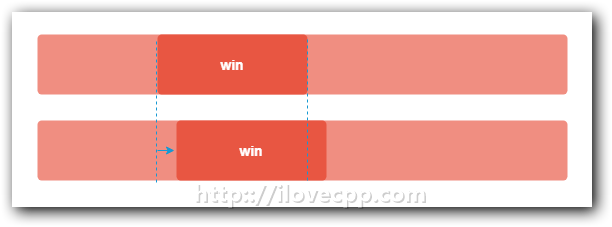
比如上图中的一个buf,win是其中的一个滑动窗口,利用Rabin算法算出win窗口中数据的指纹,随后将窗口win向后滑动一个字节,Rabin算法能够根据之前算出来的指纹迅速计算出现在这个窗口中数据的指纹。
由于该算法对数据修改不敏感,结合滑动窗口后,修改文件后分块的差异不会太大,优于固定长度分块。
当滑动窗口中的指纹与一个预设的值相匹配时就说明到了一个分块的边界,此时窗口中边界就可以被当做一个数据分割点。
Rabin指纹的算法实现在checksum.c中,暴露了通过两个函数接口操作:
1 | unsigned int rabin_checksum(char *buf, int len); |
一个根据buf和长度计算rabin指纹,另外一个是滑动1字节窗口后,根据前一个窗口指纹csum,以及滑出、滑入的字符计算一个新的指纹。
块命名
当文件被分块后,通过计算它的SHA1值为其命名。保证了每个块的唯一性。当然SHA1的唯一性不是100%的只是这个概率很小,可以忽略不计。此前Google就成功完成了全球首个SHA1碰撞:Google研究人员宣布完成全球首例SHA-1哈希碰撞!。
计算SHA1的值采用了glib里边的函数:Glib Data Checksums。
1 | void checksum (const guchar* buf,unsigned int len,uint8_t *checksum) |
以上就是对一个数据块计算SHA1的过程,整个文件的SHA1是根据最后一个快的SHA1值算出来的。是一个20位长度uint8_t数组,因为一个字节uint_t最大可以表示为0xFF,将其转为字符串的话,需要41个字节保存。utils.h里提供了转换函数:
1 | void rawdata_to_hex (const unsigned char *rawdata, char *hex_str, int n_bytes) ; |
CDCDescriptor结构
利用该实现对文件分块时,需要先初始化CDCFileDescriptor结构,其中每个字段的含义,注释如下:
1 | /* define chunk file header and block entry */ |
例如,要对一个文件分块,首先将限定的块大小设置好,并设置写块的回调函数,然后调用filename_chunk_cdc即可分块文件:
1 | void cdc_work(const char* filename) |
filename_chunk_cdc将文件打开后,将fd交给file_chunk_cdc()函数。这个就是本算法最核心的函数。
文件长度小于block_min_sz
首先file_chunk_cdc()会读入文件的实际大小,对设置的限制进行合法性验证(比如设置block_min_sz小于0等),随后计算出文件最多会被分成多少块,按这个值为CDCFileDescriptor::blk_sha1s分配空间。
1 | static int init_cdc_file_descriptor (int fd, |
先按照block_max_sz分配一个buf,这完全够用了,因为没有那个块能够超过这个长度。随后进入外层的while循坏,如果第一次从文件读入”block_min_sz - tail + READ_SIZE”长度的大小的内容,如果文件的实际长度小于block_min_sz的话:
1 | int file_chunk_cdc() |
那么说明该文件可以直接被分块,直接调用WRITE_CDC_BLOCK宏将文件写成块。写块的过程不多赘述,以块的SHA1值对应的字符串为文件名。
文件长度大于block_min_sz
如果文件块超过了设置的最小块长度的话那么说明文件可能被分块了,注意只是可能,分为两种情况
- 也有可能是1块,如果文件长度在block_min_sz和block_max_sz之间,滑动窗口一直滑动到文件尾,Rabin指纹都没有找到一个切割点。
- 其他情况下,文件都可能被分块,要么是block_min_sz和block_max_sz之间找到了一个切割点,要么是文件长度大于了block_max_sz。
现在使用FileCDC对一个较大的文件分块,第一步的过程和上面的一样,但是在判断”tail < block_min_sz || cur >= tail”的时候条件不成立,就走到这里的流程:
1 | int file_chunk_cdc() |
cur代表了文件的分割点,首先分割点肯定从block_min_sz开始,要是cur小于block_min_sz,就将cur置为block_min_sz-1(因为buf下标从0开始的)。
内层的while循坏里,滑动窗口正式登场。如果”cur == block_min_sz - 1”,说明这是第一个窗口就利用finger()函数计算Rabin指纹,否则就利用rolling_finger()函数滑动计算Rabin指纹,rolling_finger()会利用上一次的指纹来计算这次窗口里buf的指纹,速度很快,这个就是Rabin的核心原理。其中finger和rolling_finger是一个宏,分别表示rabin_checksum和rabin_rolling_checksum()。
下面的if判断条件成立表示了两种可能的分块情况:
- (fingerprint & block_mask) == ((BREAK_VALUE & block_mask)) 成立,表示这是Rabin指纹的一个分割点,文件从这里分块。
- cur + 1 >= file_descr->block_max_sz 成立,表示当前块一直到block_max_sz也为找到分割点,文件也必须分块。
分块候,和刚才一样调用WRITE_CDC_BLOCK宏,将文件写块,保存。
要是if里边的条件不成立,则表示当前不是文件分割点,调用”cur++”将窗口往后滑动一字节。开始新一轮寻找分割点。如此往复直至最终整个文件都被分块。
最后为整个文件生成一个SHA1返回给file_descr保存。至此所有文件被分块保存,file_descr->blk_sha1s里记录了每一个块的SHA1值,file_descr->file_sum里记录的是整个文件的SHA1值。
到此整个基于文件内容的可变长度分块算法内容全部结束。