经常看到网上对Raft 论文 5.4.2 一节的讨论,这里记录一下我对这个问题的理解。
论文开头是这么描述的:
A leader knows that an entry from its current term is committed once that entry is stored on a majority of the servers. If a leader crashes before committing an entry, future leaders will attempt to finish replicating the entry. However, a leader cannot immediately conclude that an entry from a previous term is committed once it is stored on a majority of servers.
后续的领导人不能判断之前任期里的日志在被复制到多数派的服务器后,就一定被马上被提交了。换句话说,也就是说领导人并不知道之前的任期的日志是否已经被提交,即使这条日志已经被复制到了多数派的服务器上。根据 Raft 协议,这条日志是不能被直接提交的。
在探究为什么之前,我们先假设:如果后续的领导人在当选后,发现之前任期的一条日志已经被复制到多数派的服务器上,直接提交这些日志会发生什么?
论文中的 Figure 8,描述了这样的场景:
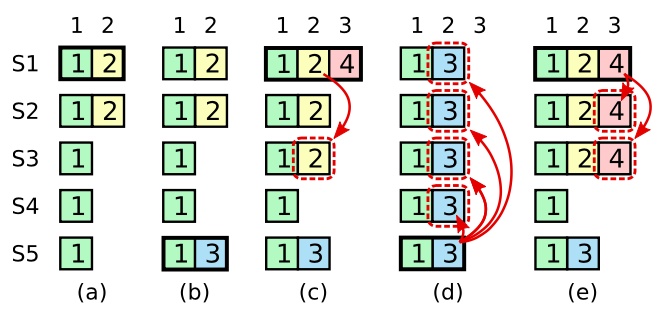
- (a) S1 是 Term 2 的 Leader,复制了一条日志(Term:2,Index:2)到 S2
- (b) S1 crash,S5 获得 S3、S4 和 S5 的投票成为 Leader,然后写了一条日志(Term:3,Index:2)到本地
- (c) S5 crash,S1 复活并且重新当选 Leader(Term 4),开始继续复制日志(Term:2,Index:2)到多数派服务器上(S1,S2,S3)上。然后又新写入一条日志(Term:4,Index:3)到本地
日志(Term:2,Index:2)已经完成了多数派的复制,如果当前的 Leader S1 (Term 4)直接提交了这条日志。
- (d) S1 crash, S5 当选 Leader (Term >= 5, 选票可以来自 S2,S3,S4,S5) ,并将日志(Term:3,Index:2)复制到其他所有节点并成功提交
日志(Term:2,Index:2)虽然已经提交,却因为 conflict 被 truncate 掉了。详情见论文 Figure 2 日志复制 RPC 的描述:If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it。
于是 Index = 2 的日志就被提交了两次,一次是 Term = 2 ,一次是 Term = 3。对于 Raft 状态机来说这是绝对不允许存在的。
- (e) 如果(C)中,S1 写入日志(Term:4,Index:3)后,没有马上 crash,这条日志被成功复制到多数派的节点(S1,S2,S3),S5 就不可能当选 Leader 了。就不存在上上述的问题。
但是在分布式系统中,网络不可靠是一个大概率的问题,情况(d) 虽然发生的概率不高,但是只要系统运行的时间足够长,这种情况总是可以出现。
为了处理 (d) 这种情况,Raft 规定:
Raft never commits log entries from previous terms by counting replicas. Only log entries from the leader’s current term are committed by counting replicas; once an entry from the current term has been committed in this way,then all prior entries are committed indirectly because of the Log Matching Property
Raft 永远不会通过计算副本数目的方式去提交一个之前任期内的日志条目。只有领导人当前任期里的日志条目通过计算副本数目可以被提交;一旦当前任期的日志条目以这种方式被提交,那么由于日志匹配特性,之前的日志条目也都会被间接的提交。
关于日志匹配性说明在论文的 Figure 3 和 5.3 节有说明:
If two entries in different logs have the same index and term, then they store the same command.
If two entries in different logs have the same index and term, then the logs are identical in all preceding entries.
加了这样的约束之后,重新回到 (C) ,日志(Term:2,Index:2)到多数派服务器上(S1,S2,S3)上后,虽然已经完成了多数派复制,但是当前的 Leader Term = 4,不能提交日志(Term:2,Index:2)。
再看 (d) , S1 crash 后,S5 当选 Leader (Term >= 5), 日志(Term:3,Index:2)复制到其他所有节点, 根据刚才 Raft 的约束,此时该条日志也是不被允许提交的。只有当 S5 接受到客户端新的命令之后,新的当前任期的日志被提交之后,Index = 2 的日志才能被顺带着提交。
于是新的问题出现了,假如 S5 迟迟等不来客户端新的写命令,Index = 2 的日志就一直不会提交,自然这条日志也就不能被应用(Apply)到状态机,恰好这个时候,S5 又收到一条来自客户端的查询请求,并且这个请求依赖于 Index = 2 的日志的应用,S5 只能返回一条旧数据。又一次违反了一致性的要求。
Raft 引入 no-op 日志的概念(该日志只包含 Term 和 Index,数据为空)来解决这个问题。Leader 当选的时候,会立即写入一条 no-op 日志。当这条日志被写入多数派节点后,no-op 日志被提交,前面的日志也会被顺带着提交了。
至此大功告成,任他风吹雨打。